February 08, 2023
(Last Update: November 02, 2024)
A Higher-level Perspective on Systems On-Call Monitoring
System "on-call" maintenance is a critical component of many technology companies.
It often requires one (or even more) engineer available 24/7 to respond to unexpected incidents quickly and efficiently. Any business wants to minimize the cost of such disruption, and this is particularly true for technology companies that are growing bigger. Whether it’s at night or in the middle of the day, proper on-call maintenance will reduce the cost of downtime and failures, and is also necessary to meet any SLA contractual requirements. 👍
Setting up an on-call team and supporting rapid “incident response times” comes at a cost and bring a whole extra set of responsibilities on developers. It must be done right and procedures need to be clear.
- For engineers who have experienced being on-call, this article aims at providing a “higher-level” perspective of the challenges and requirements of putting in place an on-call plan.
- For team leaders trying to implement an on-call procedure, this article tries to provide insights into the different technical and business aspects of infrastructure maintenance.
Everything Went Wrong (The On-Call Engineer’s Perspective)
Imagine this.
It's 3:00 AM and you are woken up by the sound of your phone buzzing. You already recognize this unmistakable ringtone… However, you are still secretly hoping that this is merely a dream. Painstakingly, you reach towards your phone, unlock it, and read the details from the production systems: payment systems are failing.
You grumble, rub your eyes, and get out of bed. There is no time to lose but you are still half asleep and can only go so fast.
You stumble to your computer, blink away the grogginess of sleep, crack your fingers, and get on Slack, informing the team that “you’re on it” even though you are not really realistically expecting any reply at this time of the night.
You diagnose the issue... and it’s really bad.
- 💀 The main payment modules are all dead.
- 💯 There is one backup node, but it’s barely holding up at 100% usage, it might break soon if nothing is done. It can not wait until tomorrow.
- ❌ The payment operations with lower priorities are already failing and accumulating in the queue.
You decide to initiate a reboot procedure, this will take some time but this is the safest way forward because we at least know all the steps. Trying to resurrect it with random magic commands would be too risky.
After two hours, the systems are back running smoothly and the bug is gone. Failed payments are being retried in the background. With a sigh of relief, you turn off your computer after notifying the team about the resolution and leaving a suggestion about increasing the capacity of the backup node + first hints for tomorrow’s root cause analysis.
You head back to bed.
Thinking globally (The CTO Perspective)
The CTO hears about the incident, and how “close we got to a complete disaster” because of the payment systems failure. “We were lucky.”
But from her perspective, it is nothing but luck. On the contrary, the team had well set up and executed an incident response procedure that proved itself useful (again…).
Surely things can be improved, and the legacy payment modules really need to be upgraded at some point, but it is also known to her that incidents happen. What matters is our ability to respond effectively.
Let’s explore the different elements that come into place behind this apparent “luck”.
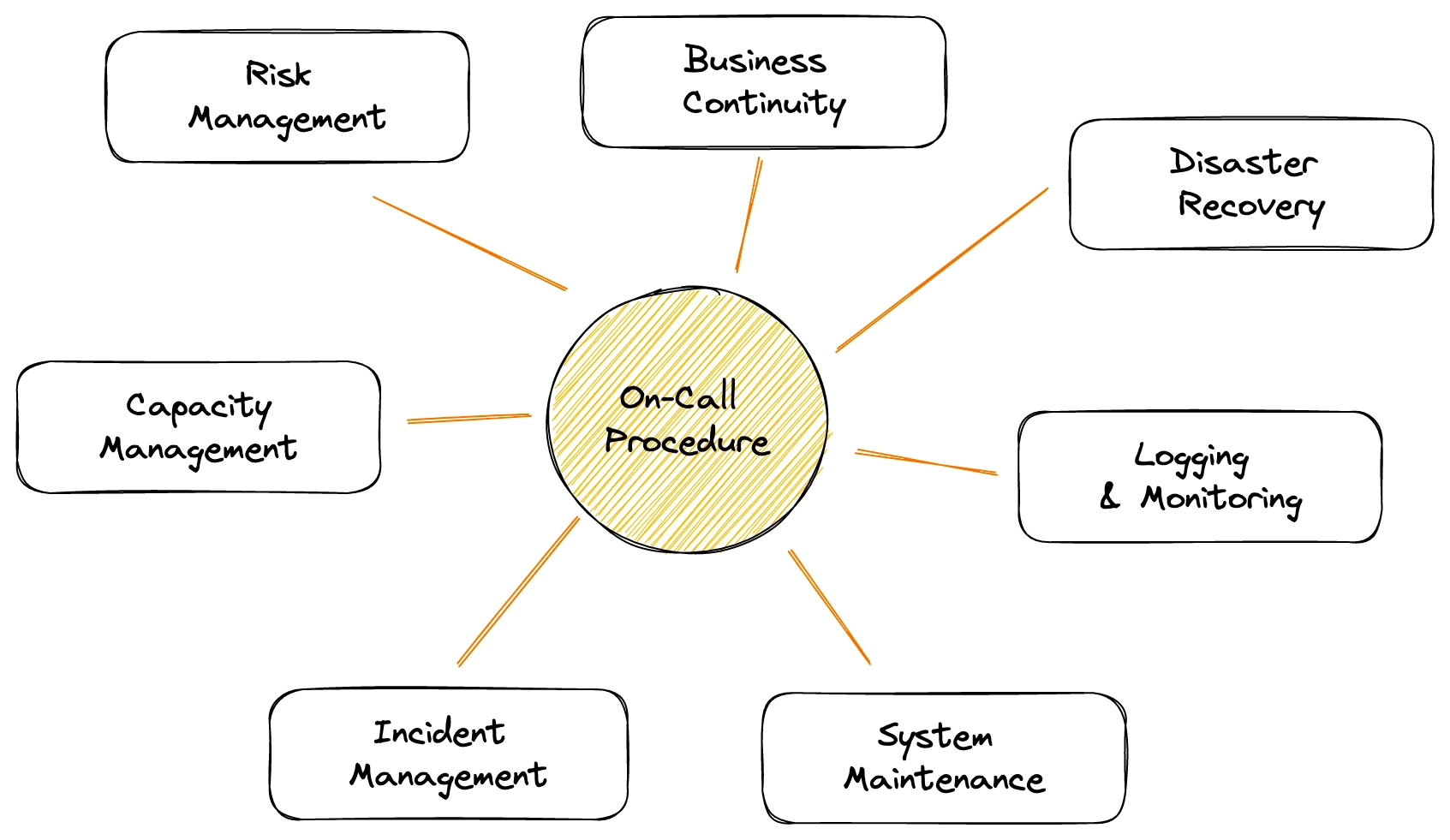
- ✅ Risk Management — When assessing the risks faced by the organization, it was decided to put in place a retry queue for payment failures. It was difficult to implement it on such a legacy system, but everything related to payment was highly prioritized considering the potential consequences. In case of incidents, the failed operations would be retried in the background and the information would never be lost, thus mitigating the impact. Thanks to this implementation, the failed recurring payments were simply executed again after the systems were backed up. The company did not risk permanently losing some of the payments, which would have been way more damaging.
- ✅ Business Continuity — As part of minimizing business disruptions and making sure systems are resilient, the SRE team implemented a failover mechanism. Backup nodes would trigger in case of a main module outage. In this case, it properly kicked in and ensured that at least the live payments were still processed (while the recurring payment has lower priorities because they are background tasks). Therefore last night, the incident was invisible to the end-users.
- ✅ Disaster Recovery — The reboot procedure really shined during the incident. It was maybe not as detailed as it could be, but the steps were more than enough for one half-asleep developer to confidently restart the module. No one enjoy maintaining the documentation for this module, but it did prove itself useful. An on-call plan is meaningless if developers do not have the knowledge, tools, and permissions to fix the system.
- ✅ Logging & Monitoring — The logs were collected, aggregated, and the alerts were properly in place to detect the anomaly in the systems. The health checks actually pinpointed that the faulty systems were the payment modules. This properly triggered an alert and the on-call process. On top of that, the error logs will be useful during the post-mortem analysis.
- ✅ System Maintenance — The on-call rotation was effective. The previous Monday, like every week, the on-call developer changed and they made sure to carry their laptop home every night and put their phone out of silence.
- ✅ Incident Management — The developer woke up and knew their duty! What if they missed the call or did not wake up? There is also a backup call in place that wakes up the CTO too if the first contact does not unlock their phone to click on the notification. During the incident, status updates were correctly sent on Slack by the engineer, and the rest of the team all read the incident report when they woke up. The proper analysis of the incident will be conducted the next day.
- ✅ Capacity Management — Not perfect, but the backup node correctly supported the load of requests during the downtime. Based on the developer’s feedback, the capacity of the backup node was increased to tackle any future incident.
Conclusion: Setting up On-Call
An on-call maintenance duty is a big step forward for small technical teams implementing it for the first time.
Depending on the size of your organization, you may have dedicated personnel for incident response and reliability or simply set up a rotation among your developers.
It plays a key role in many aspects of a business's trust and continuity, but while it can be implemented very simply (through a basic alerting system) at first, it involves a lot of high-level components from a structural perspective.
The basic components for starting an on-call procedure are easy
- 🔎 Reliable Trigger: for example an automated health check test or a rule for specific error logs.
- ⏰ Effective Notification: for example ringing the phone of the on-call developer (or a dedicated phone)
- 📝 Clear Responsibilities: the engineer needs to know what is expected in case of emergencies, where to update the team about the status, etc.

For more complex workflows and bigger teams, the flow can then be expanded and improved
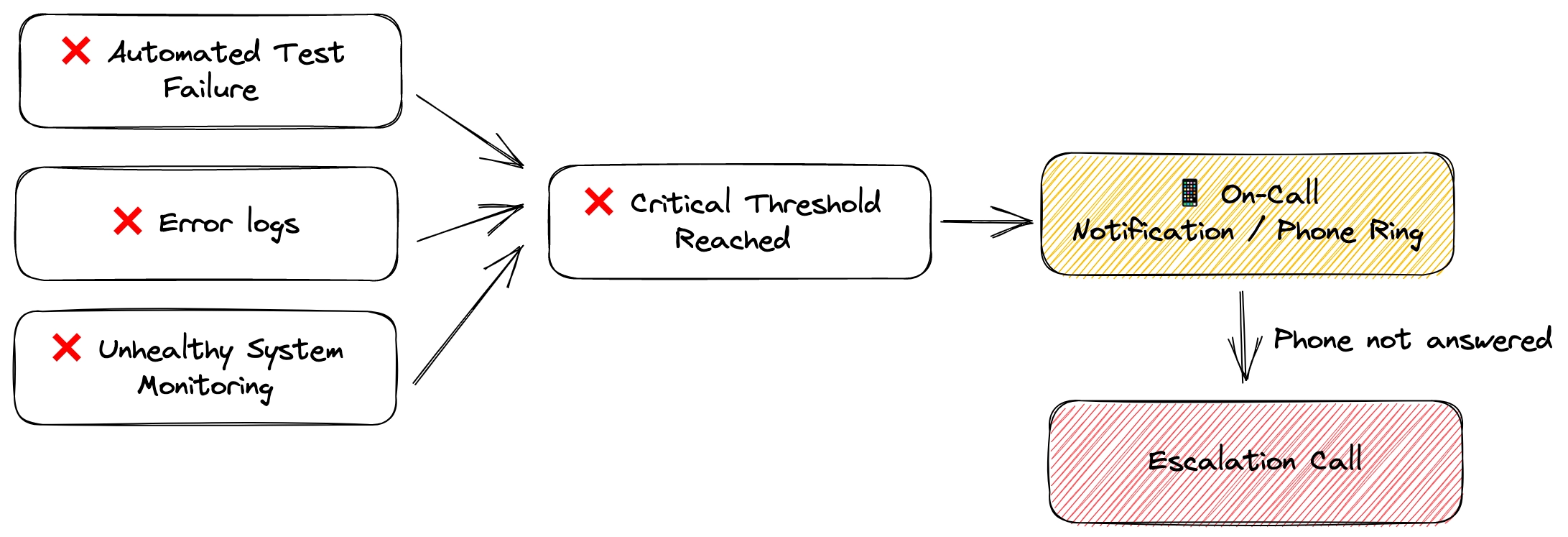
But for it to be really effective, it requires proper procedures to back it up. Technology teams don't want an on-call engineer to wake up without knowing what to do. Even worse, they don't want the engineer to misjudge the emergency or take the wrong steps, which could make the situation worse.
From a high-level perspective, teams must think about how the on-call system is useful, and how it relates to the higher goal. Some examples of topics are actually largely documented on the web and can serve as a good reference: Risk Management, Business Continuity, Disaster Recovery, Monitoring, Maintenance, Incident Management, or Capacity Management.
Defining the greater purpose of the on-call procedure and understanding its relation to other areas of the business will ensure it is effective and meaningful.