September 23, 2021
GraphQL: The Hidden Benefits

For the past year, we have asked every engineering candidate about GraphQL.
Knowing or not knowing it was never a deal-breaker, but it was always a relevant question as GraphQL plays a big role in our current tech stack.
From candidates who vaguely heard about it to the developers who used it daily, it was fascinating to hear so many different answers and opinions about the query language and its tradeoffs against more traditional approaches like REST.
It also did highlight some interesting discrepancies between the “advertised benefits” of GraphQL and some of the actual “real-life” benefits that people and teams actually experience.
This article provides an overview of the “less obvious” — yet highly impactful — advantages of using the new query language based on our own team’s experience and the experience of dozens of interviewees.
Most Common Answers
In the majority of cases, developers who heard about GraphQL before usually share the same typical understanding.
Common answer #1:
GraphQL lets developers request only the fields needed by the client.
By removing the need for fetching all the unused fields and properties. It saves bandwidth and makes the code cleaner.
✅ This answer is correct. Receiving cleaner responses is even one of the main points advertised on the GraphQL website (“Ask for what you need, get exactly that”).
✅ Reducing bandwidth usage is also true to some extent, especially if using GraphQL can transform what would otherwise be 10 different requests into a single one at the start of your application. (With or without the use the query batching and HTTP batching)
Common answer #2
GraphQL lets you manage a single endpoint.
✅ Also technically correct. But considering the required overhead of managing queries, this is at most an interesting tradeoff.
But…
These advantages are far from the main benefits of switching to GraphQL. They are the consequences of the underlying philosophy and design mindset.
If many companies are trying and adopting GraphQL, I believe their motivations go beyond “saving bandwidth” and “unifying endpoints”.
Let’s explore some impacts of GraphQL on the engineering team.
Fresh Foundations
Generally, a steep learning curve is not considered an advantage. It would more likely be a “con”.
Yet, in this case — looking back — having our team approach a whole new paradigm was very beneficial.
- ✨ It creates excitement. Learning something new is at its core what motivates every engineer. And GraphQL definitely is a new exciting thing to learn. Surely sometimes it causes some headaches at the beginning, but undeniably generates a lot of excitement.
- ⚙️ It forces everyone to “rethink” the basics and not take anything for granted. At this point, we are all used to REST in one way or another. And we do not spend the effort to “explain” it anymore or reconsider our ways. We all expect REST to be a certain way and we all have different experiences with it. “Should it return 404 or 401?”, “Should it be v2/accounts or accounts/v2?”. Everyone already has a pre-made response and fights for their ego.
With GraphQL, everybody is learning from scratch and everything is carefully and consciously designed from the basics. From authentication to error code handling, the whole team can start a discussion with a fresh and open mind, striving for good practices.
Clear Specifications
Speaking of good practices, GraphQL specifications are documented here: https://spec.graphql.org/.
That’s it: 📚 a clearly defined reference of what a proper implementation should look like.
This is a very solid and modern foundation for anyone trying to build a new API model.
Furthermore, the team at GraphQL learned from REST and has a couple of improvements built in.
Like pagination: Pagination is always way harder than it seems. There are many limitations to the most common pagination implementation, as perfectly described in this article about the limitations of traditional offset-based pagination.
GraphQL has a baked-in recipe for “cursor-based” pagination (technically from the Relay specifications, and not directly the GraphQL) which is extremely powerful: https://relay.dev/graphql/connections.htm.
If you are using a “popular” GraphQL client on the frontend, there is also a chance that this powerful pagination mechanism is already built inside the tool: Apollo has “relay-style” pagination already implemented https://www.apollographql.com/docs/react/pagination/cursor-based/#relay-style-cursor-pagination which will save a lot of engineering resources to your team.
Schema-first
An unhealthy backend-frontend relationship is often caused by inconsistencies.
Everyone hates it when:
- 💩 A User object has different properties when returned from different endpoints.
- 💩 A date is randomly returned as YYYY-MM-DD or as a timestamp.
- 💩 Data “received” needs to be refactored before being sent again to another module which expects a slightly different format.
Also, a good practice is usually to define models locally in the frontend parts, which comes with several pain points:
- 👎 Systematically redeclaring local models for API responses, which might differ or not from backend models.
- 👎 Transforming all incoming data (e.g. snake case to camel case) and transforming it back for outgoing data.
- 👎 Having different local models on different frontend applications (mobile, web…)
GraphQL has a schema-first philosophy by design. Everyone from backend to frontend should in theory always be talking about the same User object (even if we all know theory can be very different in practice). The requests expected inputs and outputs are always clearly defined by design.
A “Full-Stack” Mindset
Having a shared foundation for talking about data models also enforces a broader way of thinking. In our team, we are seeing way more constructive discussions about mutation and query design with GraphQL than discussions about REST endpoint design.
With GraphQL, it just feels like “the frontend and backend are closer”.
On the client, the simple effort of consciously having to define the queries and mutations (selecting which fields to request) enables a whole mindset. It feels natural to “move” some logic to the backend if necessary (and vice versa).
On the backend, it becomes more straightforward to build a mental model of how the frontend will use the queries and mutations. Queries — because they feel declarative — better represent a single UI view.
Similarly, mutations represent user actions but also have to return something, usually the entity that has been modified. It forces the backend to anticipate how clients will update their own local database, which at the end of the day are simply partial local representations of the entire data graph.
Code Generation
GraphQL is built with code generation in mind.
Admittedly, “codegen” is not a GraphQL exclusive feature. It is perfectly possible to use Swagger or similar tools to generate client code for REST API.
Yet, the current community and ecosystem make it really easy to start building a GraphQL API with code generation in mind (see https://www.graphql-code-generator.com/, https://github.com/apollographql/apollo-tooling).
Code generation is a powerful automation flow. It removes some friction between languages and platforms.
With GraphQL, there is one source of truth: the schema. All platforms then. have their own “implementation” of the schema. But everyone always expects the same operations, the same entities, the same enums, etc.
Documentation by Design
The industry is moving towards tools and stacks that tend to provide documentation “by design”.
These days, teams do not deploy apps and websites the same we used to do just a couple of years ago. Instead of manual migrations and procedures, we prefer to have an “in-code” configuration for our infrastructure and deployment flows (e.g. ”DevOps”).
As nicely described on puppet website:
Infrastructure-as-code Puppet is built on the concept of infrastructure-as-code, which is the practice of treating infrastructure as if it were code. This concept is the foundation of DevOps — the practice of combining software development and operations. Treating infrastructure as code means that system administrators adopt practices that are traditionally associated with software developers, such as version control, peer review, automated testing, and continuous delivery. These practices that test code are effectively testing your infrastructure. When you get further along in your automation journey, you can choose to write your own unit and acceptance tests — these validate that your code, your infrastructure changes, do as you expect.
Our team uses Altair which automatically creates a documented playground that updates in real-time. On every backend deployment, the app will update its documentation:
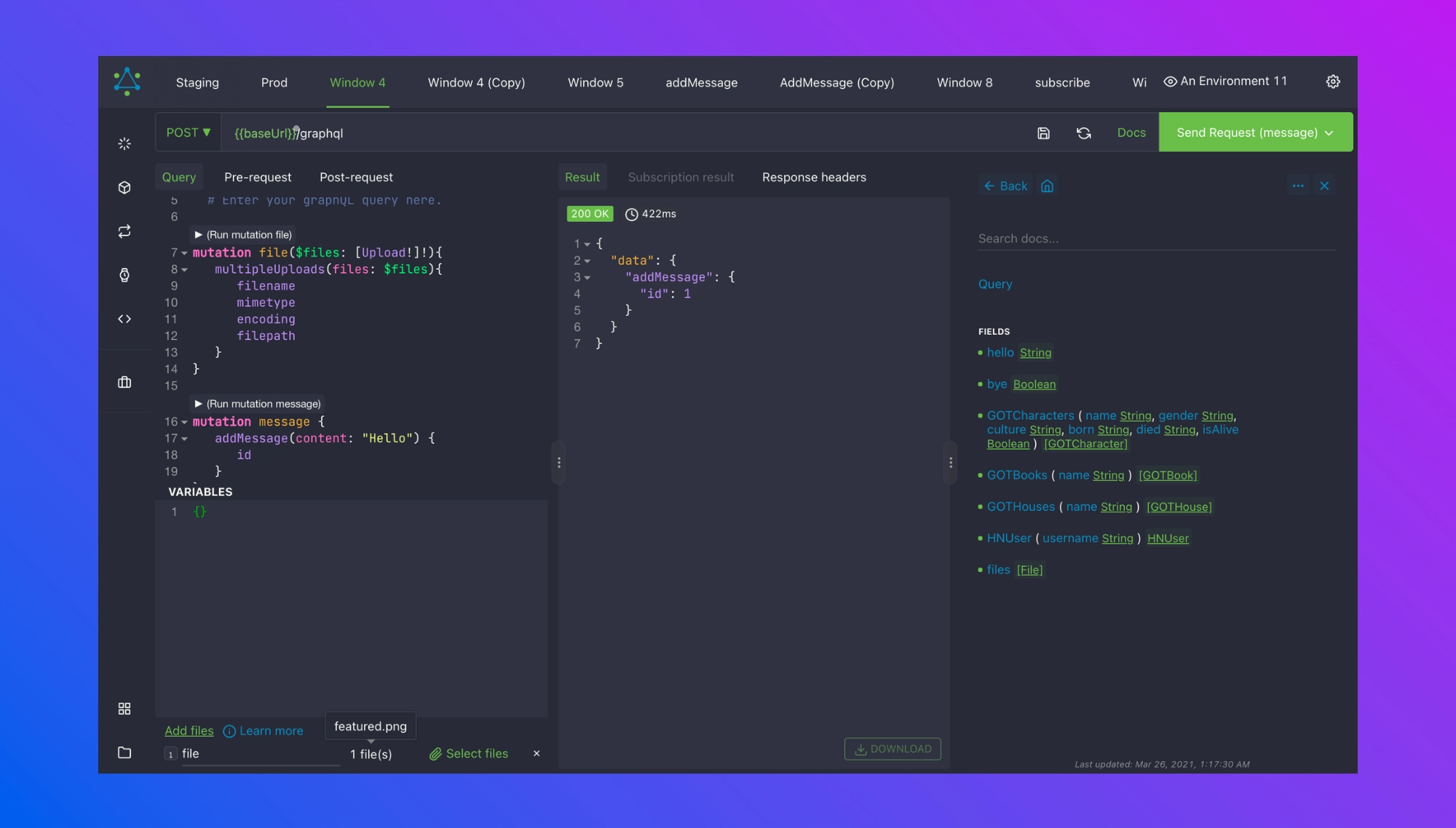
It lists all the operations, with the expected inputs and outputs. It even supports directives (like @DEPRECATED) to always make sure everyone is on the same page!
Conclusion
GraphQL can be considered “new” (The stable release is from June 2018) compared to a well-established architecture like REST. And it is refreshing from a technical perspective to have a different paradigm for designing and playing with API endpoints.
Beyond the pure technical benefits, I was personally very pleasantly surprised about the transformative impact GraphQL had on teamwork and collaboration. To me, it opens a whole new mindset for developers to juggle between frontend and backend. If executed properly, it can definitely make teams work together more effectively.